行锁:锁某行数据,粒度最小,并发度搞
表锁:锁整张表,力度最大,并发度低
间隙锁:锁一个区间
共享锁:其他事务能读不能写
排他锁:其他事务不能读也不能写
乐观锁:通过版本号实现
悲观锁:行锁表锁都是悲观锁


如何优化:
检查是否走索引
检查是否查询了过多的字段,查出过多的数据
数据记录是否过多,分库分表
检查配置是太低
EXPLAIN
索引覆盖:所有需要的字段都在索引里,不用回表
最左匹配原则:是原则也是限制
innodb如何实现事务的?
Buffer Pool, LogBuffer, Redo Log, Undo log
update:缓存到buffer pool=> x修改buffer pool 内的数据=》生成redolog对象,存入logbuffer=》生成undolog日志,用于回滚=》
如果提交事务=》redolog持久化,后续其他机制将buffer log中修改的数据(脏页)持久化到磁盘
如果回滚=》利用undolog回滚
索引原理:把无序的数据变成有序的查询
.把创建索引的内容进行排序
.生成倒序表
.拼接地址链
.拿到倒排表 拿到地址链
聚簇索引和非聚簇索引的区别
都是B+数
聚簇索引:将数据存储和索引放到一块、按照一定顺序组织的
优势:可以直接取到数据
劣势:维护索引代价很高(optimize table)
如果使用uuid做主键会导致数据非常稀疏
如果主键比较大的话,辅助索引将会变大,因为存了ID
非聚簇索引:叶子节点补存储数据、存储的数据行地址(ID?)innodb是存的id
主键一定是聚簇索引,在聚簇索引上建的索引是辅助索引
innodb一定有主键
MyISM无需访问主键索引树

B+树:平衡的多叉树,叶子节点高度差不超过1(0?)、同级节点间指针相互连接,可以快速左右移动
、Hash索引:一张哈希表,不能范围查询,不能模糊查询,不支持最左匹配,只支持单条等值查询
二叉树:2个节点

共享锁:读锁,支持并发读取,读的时候不支持修改
排他锁:写锁,其他请求不能读取和修改,避免出现脏数据和脏读的问题。
表锁:
行锁:可以锁多行
记录锁:锁一行,使用唯一索引,可以避免重复读问题,也避免了在修改的事务未提交前被其他事务读取的脏读问题。
页锁:会出现死锁,一次锁定相邻的一组记录
间歇锁:行锁的一种,锁住表记录的某个区间,左开又闭
临建锁:记录锁和间歇锁的组合
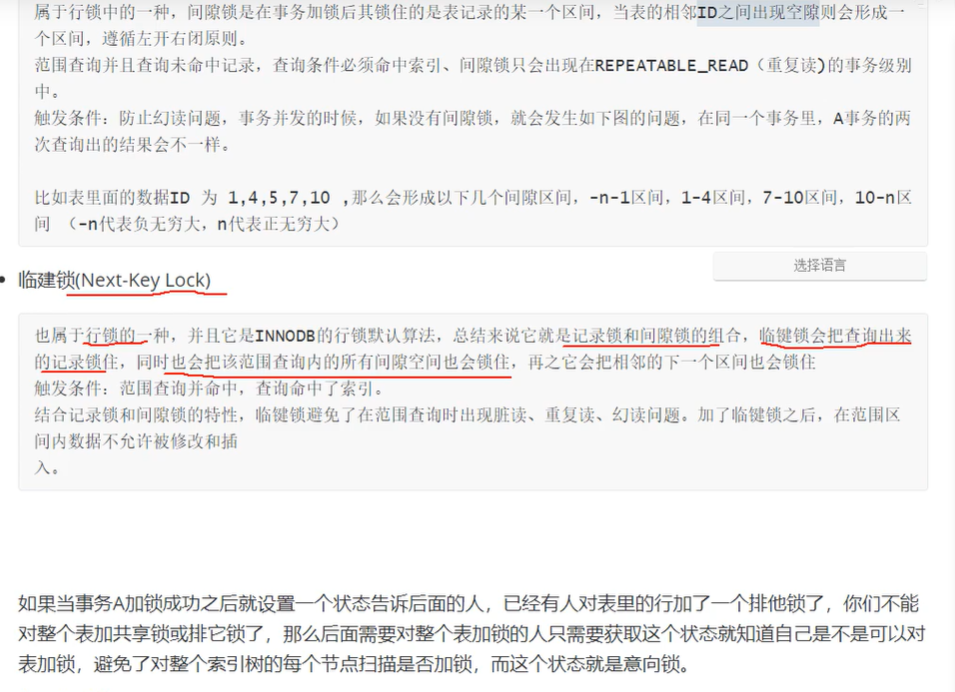
意向共享锁:
意向排他锁:
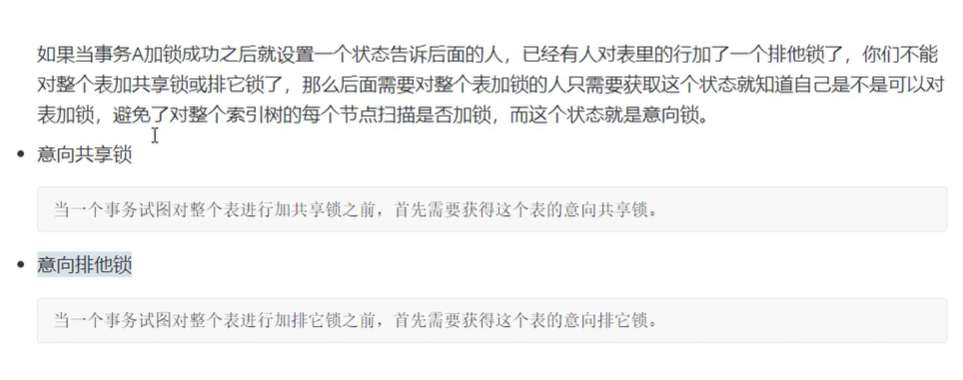
提高加锁的效率
innodb默认行锁
explain:
type:
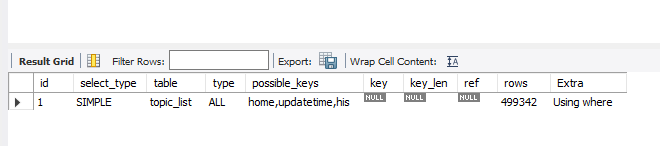



const: id=1 索引一次命中,匹配一行记录
system: 表中只有一行记录,相当于系统表
eq_ref: 唯一索引扫描
ref: 非唯一索引扫描,某个值得所有记录
range: 范围内的行
index: 只遍历索引树
All: 全表扫描
避免all和index